Swiftide 0.31 - Tasks, Langfuse, Multi-Modal, and more
Latest Swiftide ships first-class Langfuse support, graph like tasks, and more
This release ships some awesome new features. Shout-out to the users and contributors that made this possible.
I even took out my (sick) drawing skills to update the vastly outdated overview image in the readme:
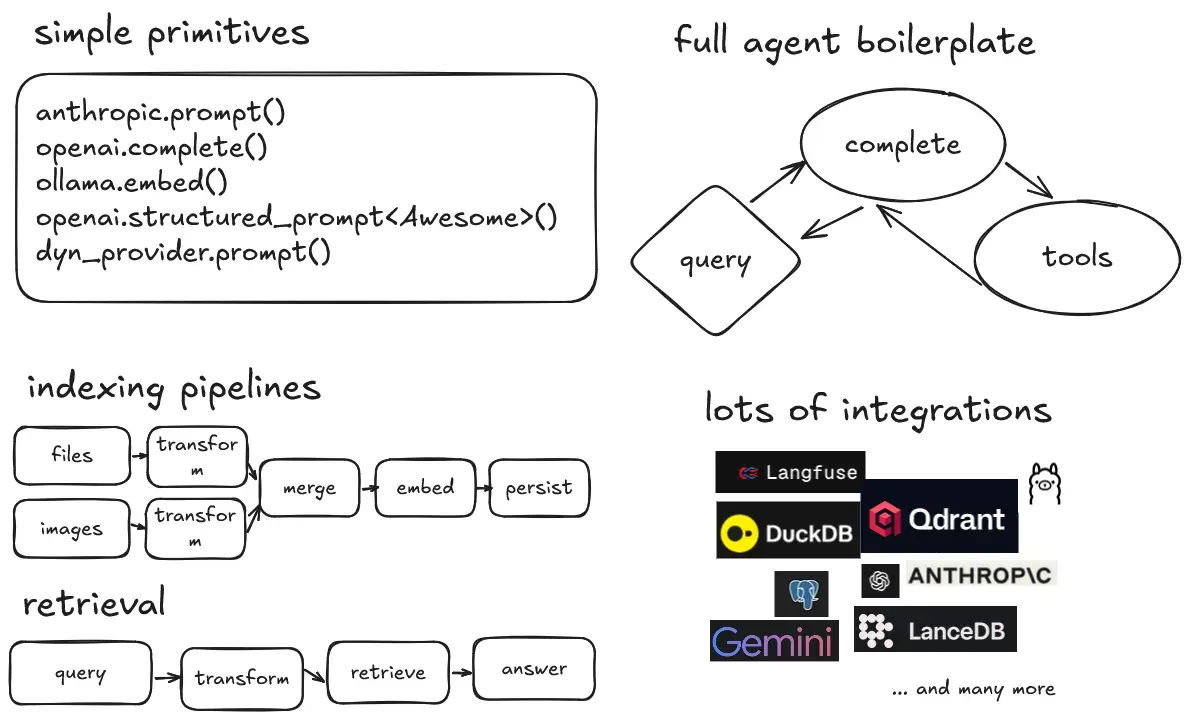
Swiftide is a Rust library for building LLM applications. From performing a simple prompt completion, to building fast, streaming indexing and querying pipelines, to building agents that can use tools and call other agents.
To get started with Swiftide, head over to swiftide.rs, check us out on github, or hit us up on discord.
Langfuse integration with tracing
Instrumentation provided by tracing is already pretty great. However, with LLM heavy applications, we want to be able to observe the input and outputs, costs, and flow of conversation more easily. Langfuse is a fantastic tool to do just that.

Swiftide now has first class support for Langfuse. You can enable it by adding the langfuse feature flag, and setting up tracing like normal:
let fmt_layer = tracing_subscriber::fmt::layer() .compact() .with_target(false) .boxed();
let langfuse_layer = swiftide::langfuse::LangfuseLayer::default() .with_filter(LevelFilter::DEBUG) .boxed();
let registry = tracing_subscriber::registry() .with(EnvFilter::from_default_env()) .with(vec![fmt_layer, langfuse_layer]);
registry.init();Refer to the documentation for more details and configuration options. Langfuse has a handly docker compose file to get started quickly.
More convenient usage reporting
Usage reporting was a bit convoluted. Previously it was already possible by enabling metrics and using metrics-rs, but honestly, it felt like a lot of work for something that should be really easy to do.
What I really wanted to do is to uniformly report on any LLM calls made by a provider, without having to worry about it when doing the work.
There is now a on_usage and on_usage_async1 hook in the LLM providers that aims to solve this. Simple example:
let openai = openai::OpenAI::builder() .default_prompt_model("gpt-5") .on_usage(|usage| println!("{usage}")) .build()?;
openai.prompt("What is the capital of France?".into()).await?;Structured prompts
This has been on my wish list for a long time. LLMs are amazing at quickly’ish classifying large amounts of unstructured (and unrelated) data. For us, it allows us to classify code chunks, issues, and so on.
You can define your structure with a rust struct, derive from schemars::JsonSchema, and it will work as advertised:
#[derive(Deserialize, JsonSchema, Serialize, Debug)] #[serde(deny_unknown_fields)] // IMPORTANT! struct MyResponse { questions: Vec<String>, }
let response = client .structured_prompt::<MyResponse>( "List three interesting questions about the Rust programming language.".into(), ) .await?;
println!("Response: {:?}", response.questions);
// Because we use generics, structured_prompt is not dyn safe. However, there is an // alternative:
let client: Box<dyn DynStructuredPrompt> = Box::new(client);
let response: serde_json::Value = client .structured_prompt_dyn( "List three interesting questions about the Rust programming language.".into(), schemars::schema_for!(MyResponse), ) .await?;
let parsed: MyResponse = serde_json::from_value(response)?;Not implemented for Anthropic, it’s not great at these kind of tasks.
Graph like workflows with Tasks
Swiftide now has a simple, typed task construct for combining all of its primitives and not-so-primitives to create interesting graph like workflows. Shout-out to PocketFlow for the inspiration.
Under the hood the simplicity of it all really makes it a cool tool to use. Bosun’s workflows uses these under the hood for its workflows.
When created, tasks take a generic Input and Output as its generic parameters.
Conceptually, you register nodes. Whenever you do, the id of that node is returned. You can then register transitions between those nodes. Finally you need to specify what node it starts with and when the task ends.
let openai = swiftide::integrations::openai::OpenAI::builder() .default_embed_model("text-embeddings-3-small") .default_prompt_model("gpt-4o-mini") .build()?;
let agent = agents::Agent::builder().llm(&openai).build()?;
let mut task: Task<Prompt, ()> = Task::new();
let agent_id = task.register_node(TaskAgent::from(agent));
let hello_id = task.register_node(SyncFn::new(move |_context: &()| { println!("Hello from a task!");
Ok(()) }));
task.starts_with(agent_id);
// Async is also supported task.register_transition_async(agent_id, move |context| { Box::pin(async move { hello_id.transitions_with(context) }) })?; task.register_transition(hello_id, task.transitions_to_done())?;
task.run("Hello there!").await?;The TaskNode trait is implemented for (most) Swiftide primitives. In a real world scenario you will probably want to implement your own. For example:
#[async_trait]impl TaskNode for Box<dyn SimplePrompt> { type Input = Prompt; type Output = String; type Error = LanguageModelError;
async fn evaluate( &self, _node_id: &DynNodeId<Self>, input: &Self::Input, ) -> Result<Self::Output, Self::Error> { self.prompt(input.clone()).await }}Nodes and transitions also work with their dyn variants for the adventurous!
Tasks allow you to create intricate multi-agent setups. Bonus; there are new stop tools that can take an output.
Preparing for multi modal indexing pipelines
One limiting feature of the indexing pipeline, is that it could only index strings. The groundwork is now done (and it’s already useable) for all steps to be generic over the indexed value. Even cooler, the type can change mid-way!
This enables some really cool (future) stuff:
- Load unstructured, then classify, mangle, and get fully typed and structured data (bonus; new
StructuredPrompttrait) - Multi modal indexing
- Splitting streams into different types of streams
To make this work, the indexing pipeline and all its components are now generic over its internal type, bound by a new Chunk trait.
That trait is defined as follows:
pub trait Chunk: Clone + Send + Sync + Debug + AsRef<[u8]> + 'static {}impl<T> Chunk for T where T: Clone + Send + Sync + Debug + AsRef<[u8]> + 'static {}The blanket implementation makes sure it works for any owned type that can be referenced by its bytes. Remember you can always use an owned type pattern if your type of choice does not work out of the box.
All indexing traits now have a type Input: Chunk and/or type Output: Chunk as associated types.
To upgrade to this new version, you will need to add the associated types to your implementations. If you used String before, you can just add type Input = String; type Output = String; to your implementations.
Most example transformers now take a Node<T: Chunk> or a Node<String>. For convenience, there is a TextNode alias for Node<String>.
Aside: Docker executor updates
Agent tools can run in a ToolExecutor. By default this is local, but we also have one for docker. Over the months, it got some cool new features:
- Can act as a file loader for indexing pipelines
- Docker compose support
- Run
shebangmulti line scripts - Support running tasks in the background when suffixed with
& - Configurable defaults for environment variables
The executor makes it super easy for us to spin up an isolated environment for our agents to work with.
But wait there is more
In addition to all this, there are loads of fixes, improvements, and updates. The full changelog is on github.
If you’re interested in contributing, would love to see a feature, ideas for better documentation, or otherwise would like to get involved, join us on Discord.
To get started with Swiftide, head over to swiftide.rs or check us out on github.
Footnotes
-
Still playing with different closure apis. The new AsyncFn api unfortunately does not allow setting Send and a lifetime on stable. Since the async variant takes a Box::pin(async {}) as return value, trying to see if having both makes the api nicer to use. I’ll buy a drink of choice for the killer solution that makes it uniform. ↩